13 Open-Source Solutions for Running LLMs Offline: Benefits, Pros and Cons, and Should You Do It? Is it the Time to Have Your Own Skynet?


As large language models (LLMs) like GPT and BERT become more prevalent, the question of running them offline has gained attention. Traditionally, deploying LLMs required access to cloud computing platforms with vast resources. However, advancements in hardware and software have made it feasible to run these models locally on personal machines.
This post explores the benefits and drawbacks of running LLMs offline, the minimal system requirements, and how to implement this on macOS, Windows, and Linux.
Why Run LLMs Offline?
Running LLMs offline offers several key advantages, especially for developers, researchers, and organizations with unique privacy or operational needs.
Benefits of Running LLMs Offline
- Data Privacy: Running LLMs locally ensures sensitive data never leaves your system. For organizations handling confidential or personal information (e.g., healthcare, finance), this is crucial for regulatory compliance.
- Cost Efficiency: Cloud services can be costly, particularly when running models at scale. Running LLMs offline eliminates recurring fees for cloud usage, data transfers, and compute time.
- Customization and Flexibility: You have full control over the hardware and software environment, allowing you to fine-tune models, optimize performance, and customize them according to specific needs without cloud restrictions.
- Low Latency: Running models offline reduces network-related latency, enabling faster responses in real-time applications like chatbots, virtual assistants, and other AI-driven tools.
Drawbacks of Running LLMs Offline
- Hardware Requirements: LLMs are resource-intensive. Running them offline requires significant computational power, memory, and storage, making it challenging for older or low-end machines.
- Maintenance and Updates: Managing LLMs offline means you're responsible for updating, maintaining, and troubleshooting the models, which may require technical expertise.
- Lack of Scalability: Scaling up LLM operations on local hardware is limited by your resources. For larger, enterprise-scale tasks, the cloud may still be a better option for efficiency and ease of scaling.
Should You Run LLMs Offline?
Running LLMs offline offers significant advantages in privacy, cost control, and real-time performance. However, it demands substantial hardware resources and technical expertise. For small-scale projects or situations where data privacy is paramount, offline deployment can be highly advantageous. Yet, for large-scale applications requiring scalability and frequent updates, cloud services often prove more efficient.
Your decision to run LLMs offline should hinge on your specific needs, hardware capabilities, and project scale. If you're tinkering with small models or require stringent data privacy, exploring offline LLM deployment is worthwhile. For broader applications, however, cloud-based LLM services may offer a more practical solution.
Minimum System Requirements to Run LLMs Offline
Before attempting to run an LLM on your local machine, it's important to understand the minimum hardware specifications.
For small to medium-sized models, here's a general breakdown:
- Processor (CPU): A high-performance multi-core CPU (e.g., Intel i7 or AMD Ryzen 7). Some models may require support for AVX instructions for better performance.
- Graphics Card (GPU): A modern NVIDIA GPU with at least 8-12 GB of VRAM (such as an RTX 3060 or higher) is recommended for accelerated computations, though some models can run on CPUs (albeit slowly).
- Memory (RAM): At least 16GB of RAM for smaller models. For larger models, 32 GB or more is ideal.
- Storage: SSD storage is recommended for fast data access, with at least 50-100 GB of available space, depending on the model size.
1- GPT4All
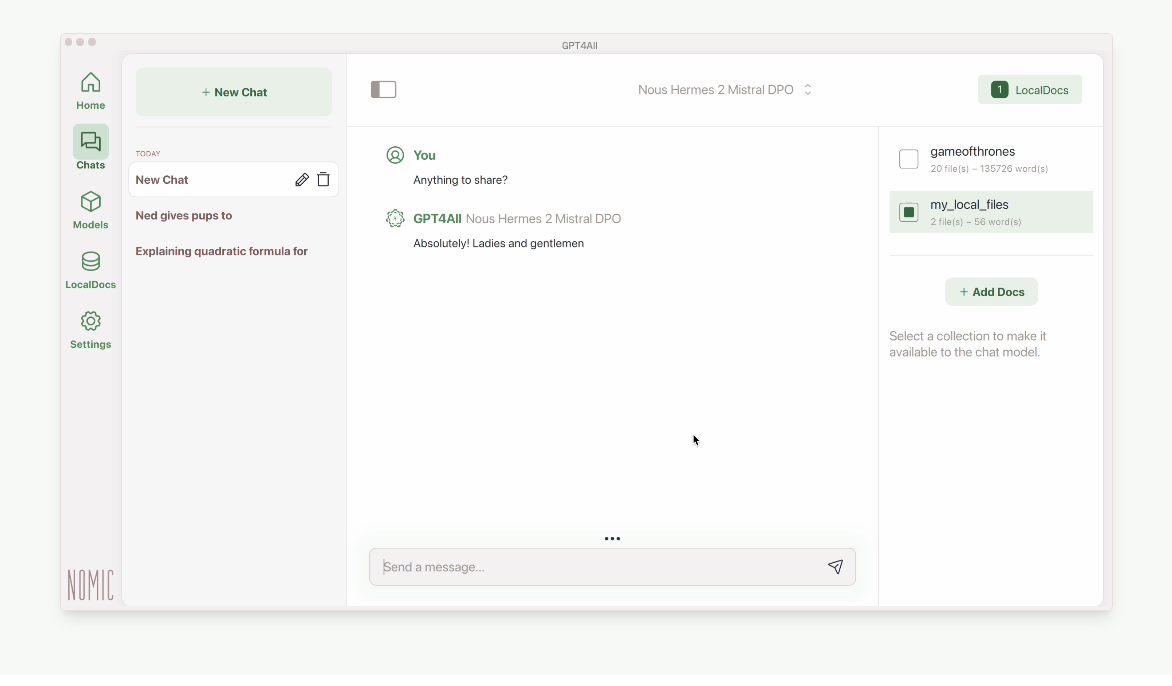
The GPT4ALL is a free and open-source ecosystem of local large language models. It offers a Python and C++ API for easy integration, and includes a chat client with a user-friendly interface for direct interaction with various language models.
It supports over 1000 open-source language models, local files, and smaller hardware
The app works for Windows, Linux and macOS.
2- OpenLLM
OpenLLM is an open-source platform designed for operating large language models (LLMs) in production environments. Here's a summary of its key features:
- It supports various models and provides capabilities for fine-tuning, monitoring, and deployment in both cloud and on-premises environments.
- Written in Python, OpenLLM offers easy-to-use functionality that allows developers to run any open-source LLMs (such as Llama 3.2, Qwen2.5, Phi3, and others) or custom models.
- It enables running these models as OpenAI-compatible APIs with a single command.
- OpenLLM includes a built-in chat UI for user interaction.
- It features state-of-the-art inference backends for efficient model operation.
- The platform provides a simplified workflow for creating enterprise-grade cloud deployments using Docker, Kubernetes, and BentoCloud.
These features make OpenLLM a versatile and powerful tool for developers and organizations looking to leverage LLMs in their applications or services.
 bentoml
bentoml3- Open WebUI
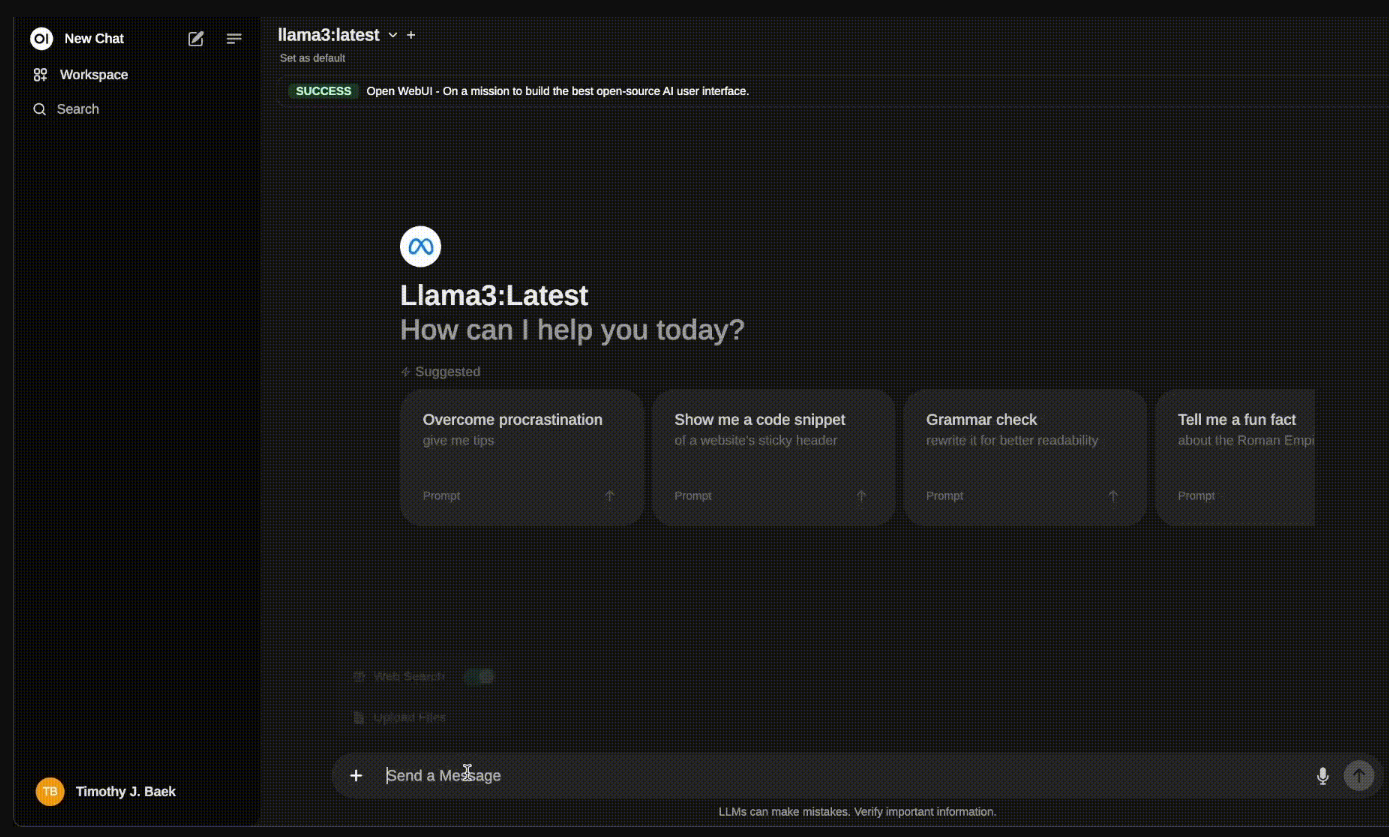
OpenWebUI is a super user-friendly web interface for running and interacting with large language models. It offers features like conversation management, model switching, and custom prompts, making it easier for users to work with different AI models.
Key Features of Open WebUI
- 🚀 Easy Setup: Docker or Kubernetes installation
- 🤝 API Integration: Supports Ollama and OpenAI-compatible APIs
- 🧩 Plugin Support: Custom logic and Python libraries integration
- 📱 Responsive Design: Works on desktop and mobile devices
- 📱 Progressive Web App (PWA): Native app-like experience on mobile
- ✒️ Markdown and LaTeX Support: Enhanced text formatting
- 🎤 Voice/Video Call: Hands-free communication features
- 🛠️ Model Builder: Create and customize Ollama models via Web UI
- 🐍 Python Function Calling: Built-in code editor support
- 📚 Local RAG Integration: Document interaction in chat
- 🔍 Web Search for RAG: Multiple search provider options
- 🌐 Web Browsing: Integrate websites into chat
- 🎨 Image Generation: Local and external options available
- ⚙️ Multi-Model Conversations: Engage with various models simultaneously
- 🔐 Role-Based Access Control: Secure access management
- 🌐 Multilingual Support: i18n for multiple languages
4- LM Studio
LM Studio is a free project for running large language models locally on your personal computer. It offers a graphical interface for downloading, managing, and interacting with various AI models without requiring coding skills.
LM Studio aims to simplify the integration of AI capabilities into applications by providing user-friendly tools, comprehensive documentation, and APIs that enable developers to effectively leverage LLMs.
Its features of LM Studio include support for both training and fine-tuning language models, allowing customization for specific use cases.
The app emphasizes scalability and flexibility, making it suitable for enterprise-level AI deployments as well as smaller-scale projects.
5- WebLLM
WebLLM is a high-performance in-browser LLM inference engine that brings language model inference directly to web browsers with hardware acceleration. It runs entirely inside the browser without server support and is accelerated using WebGPU.
WebLLM is fully compatible with the OpenAI API. This means you can use the same OpenAI API on any open-source models locally, with features including streaming, JSON mode, and function calling (work in progress).
Features:
- Extensive Model Support: Supports Llama 3, Phi 3, Gemma, Mistral, Qwen, and more
- In-Browser Inference: High-performance LLM operations using WebGPU acceleration
- Custom Model Integration: Deploy custom models in MLC format
- Chrome Extension Support: Build basic and advanced browser extensions
- Full OpenAI API Compatibility: Streaming, JSON-mode, logit control, seeding
- Web Worker & Service Worker Support: Optimize performance and manage model lifecycle
- Structured JSON Generation: State-of-the-art JSON mode with WebAssembly optimization
- Plug-and-Play Integration: Easy integration via NPM, Yarn, or CDN
- Streaming & Real-Time Interactions: Enhance interactive applications like chatbots
6- OnPrem.LLM
This is a developer-friendly Python library for deploying and using large language models on-premises. It simplifies the process of running models locally (on-premises), making it easier for developers to integrate AI capabilities into their applications without relying on cloud services.
amaiya7- LLMFarm
LLMFarm is an open-source project that streamlines the process of working with large language models (LLMs). It offers a versatile and scalable framework for deploying, fine-tuning, and serving these models. Designed for developers and organizations needing on-premise AI solutions, LLMFarm provides a comprehensive set of features to simplify the entire lifecycle of LLMs.
Key Features of LLMFarm
- Scalable: Manage multiple LLMs concurrently
- Customizable: Fine-tune models for specific industries
- Efficient: Deploy on standard hardware with low latency
- User-friendly: Intuitive interface for easy model management
- Apple Silicon compatible: Supports M1, M2, and Intel-based Macs
- Resource-efficient: Optimized for various hardware configurations
Supported Models
LLMFarm supports a wide range of state-of-the-art language models, including:
- GPT variants
- BERT (Bidirectional Encoder Representations from Transformers)
- T5 (Text-to-Text Transfer Transformer)
This diverse model support makes LLMFarm an ideal tool for developers looking to leverage different models for various natural language processing tasks. These tasks include summarization, question answering, and text classification, among others.
8- Cria
Cria is a Python library for running Large Language Models with minimal configuration. It's designed to be user-friendly, even when utilizing advanced features.
Its key features include
- Easy: Zero configuration required out of the box. Start with just five lines of code.
- Concise: Streamlined code reduces development time and eliminates redundancy.
- Local: Run LLMs offline, free from rate limits and internet dependencies.
- Efficient: Leverage advanced features using your own
ollamainstance or a subprocess.
leftmove9- safespace
safespace provides a free and open-source tool designed to create a secure environment for running large language models locally. It emphasizes data privacy and security, allowing users to leverage AI capabilities without exposing sensitive information to external services.
It helps developers ensure that user-provided HTML content is safe by filtering out potentially harmful or malicious elements, enhancing security for web applications.
10- LlamaGPT
LlamaGPT is a free self-hosted web app for interacting with the Llama language model. It provides a user-friendly way to engage with this powerful AI model, offering features like conversation history and customizable settings.
You can easily install it using Docker with full CUDA support.
11- AgentGPT
AgentGPT is an open-source project that empowers developers and users to configure and deploy autonomous AI agents. These intelligent agents can tackle a wide range of tasks and solve complex problems by breaking them down into smaller, manageable steps.
With AgentGPT, you can create your own custom AI, give it a name, and set it on any imaginable goal. The AI will work towards achieving this goal by devising tasks, executing them, and learning from the results—all while continuously adapting and improving its approach. 🚀
reworkd12- TinyLLM
TinyLLM is a project aimed at running large language models on small systems while maintaining acceptable performance. It offers a locally hosted LLM with a ChatGPT-like web interface, supporting multiple LLMs and providing features like customizable prompts and external data access. The project requires consumer-grade hardware and specific software configurations.
jasonacox13- openplayground
OpenPlayground is an LLM playground that runs on your laptop, offering a versatile interface for using various AI models. It features a full UI with parameter tuning, model comparison, and local model detection.
natHow to Run LLMs Offline on macOS, Windows, and Linux
1. macOS
Running LLMs on macOS is possible but can be challenging due to hardware limitations, particularly the absence of NVIDIA GPUs, which are preferred for deep learning.
Steps to Run LLMs Offline on macOS:
- Use CPU-Optimized Libraries: Install libraries like ONNX Runtime or Apple's Core ML to leverage the M1/M2 chip for LLM inference.
- Install a Python Environment: Set up Miniconda or Homebrew for Python-based model execution.
- Download a Pre-Trained Model: You can find pre-trained LLMs from libraries like Hugging Face Transformers or GPT-Neo and download them for local use.
Example command to install Hugging Face's transformers on macOS:
pip install transformers
Tip: Running models like GPT-2 is feasible, but larger models like GPT-3 may struggle on macOS hardware due to memory constraints.
 Hazem Abbas
Hazem Abbas
2. Linux
Linux is the preferred platform for most AI and machine learning tasks due to its flexibility, efficiency, and compatibility with a wide range of hardware and software tools.
Steps to Run LLMs Offline on Linux:
- Install GPU Drivers: Install appropriate drivers and libraries (e.g., NVIDIA CUDA Toolkit for NVIDIA GPUs) to fully utilize hardware.
- Set Up a Python Environment: Use Miniconda to manage Python libraries and dependencies.
- Run Pre-Trained Models: Download pre-trained models from repositories like Hugging Face, or use custom fine-tuning on popular frameworks like PyTorch or TensorFlow.
Example installation of necessary tools:
sudo apt-get install python3-pip
pip3 install torch transformers
Tip: Linux supports easier GPU optimization and scaling compared to Windows or macOS, making it the go-to platform for advanced LLM applications.
3. Windows
Windows has better hardware support, especially for NVIDIA GPUs, making it a more flexible platform for running LLMs offline.
Steps to Run LLMs Offline on Windows:
- Install NVIDIA CUDA: If using an NVIDIA GPU, ensure that CUDA and cuDNN are installed for GPU-accelerated model inference.
- Set Up Conda: Install Anaconda to create isolated environments for machine learning libraries like PyTorch or TensorFlow.
- Download and Fine-Tune Models: Use Hugging Face or other pre-trained models and fine-tune them for your needs.
Example of running a model locally:
pip install torch transformers
load a model
from transformers import pipeline
generator = pipeline('text-generation', model='gpt2')
print(generator("Hello, I am an LLM"))
Tip: You can optimize performance using TensorRT for inference or ONNX Runtime to maximize GPU utilization.
Wrapping up
Running LLMs offline is now within reach for developers and businesses, thanks to open-source resources and hardware advancements. With the right tools and setup, you can harness the power of AI on your local machine across macOS, Windows, and Linux.