Top 15 Open-Source Headless Browsers for Automation: Testing, Scraping, and Beyond

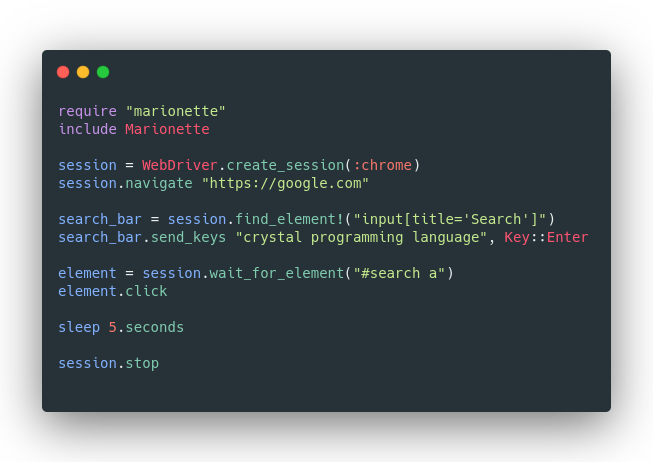
Table of Content
What is a Headless Browser?
In today's digital landscape, headless browsers have emerged as indispensable tools for developers and testers. Operating without a graphical user interface (GUI), these browsers facilitate interaction with web pages programmatically, streamlining tasks traditionally handled manually.
Let's explore the myriad applications and advantages of headless browsers.
But first, What is a Headless Browser?
A headless browser is a web browser without a graphical user interface (GUI). It allows you to interact with web pages programmatically, enabling you to perform tasks that you would normally do in a browser, but in an automated way and without any visual output.
Practical Applications of Headless Browsers
Data Extraction:
Headless browsers excel at web scraping, enabling users to extract information from websites efficiently. By bypassing the need for a visual interface, they can navigate web pages, parse HTML, and retrieve data seamlessly.
Automated Quality Assurance:
In the realm of automated testing, headless browsers play a pivotal role. They can execute test scripts on web applications, verifying functionality and performance without human intervention. This automation accelerates the testing process and ensures consistent results.
Performance Benchmarking:
Headless browsers are also valuable for performance monitoring. They can measure load times, page speed, and other critical metrics, providing insights into a website's efficiency. These benchmarks help identify bottlenecks and optimize user experience.
Snapshot Creation:
Generating screenshots of web pages programmatically is another key use case. Headless browsers can capture visual representations of web content at various stages, aiding in documentation, debugging, and visual validation.
User Simulation:
Automating user interactions is perhaps one of the most powerful features of headless browsers. They can simulate clicks, form submissions, and other actions, mimicking real user behavior. This capability is crucial for testing complex workflows and ensuring smooth user experiences.
In the following list, we offer you the best open-source headless browsers that developers can use for free for any purpose.
1. Puppeteer
Puppeteer is an open-source Node.js library providing a high-level API to control Chrome or Chromium via the DevTools Protocol. It enables automation of browser tasks such as web scraping, automated testing, and performance monitoring.
Puppeteer supports headless mode, allowing it to run without a graphical interface, and offers functionalities like generating screenshots and PDFs, simulating user interactions, and capturing performance metrics. It's widely used for its powerful capabilities and ease of integration with web projects.
 puppeteer
puppeteer2. Erik
Erik is an headless browser based on WebKit. An headless browser allow to run functional tests, to access and manipulate webpages using javascript.
phimage3. Surf
Surf is a Go (golang) library that implements a virtual web browser that you control programmatically. Surf isn't just another Go solution for downloading content from the web.
Surf is designed to behave like web browser, and includes: cookie management, history, bookmarking, user agent spoofing (with a nifty user agent builder), submitting forms, DOM selection and traversal via jQuery style CSS selectors, scraping assets like images, stylesheets, and other features.
headzoo4. Serverless Chrome
Serverless Chrome contains everything you need to get started running headless Chrome on AWS Lambda.
adieuadieu5. Marionette
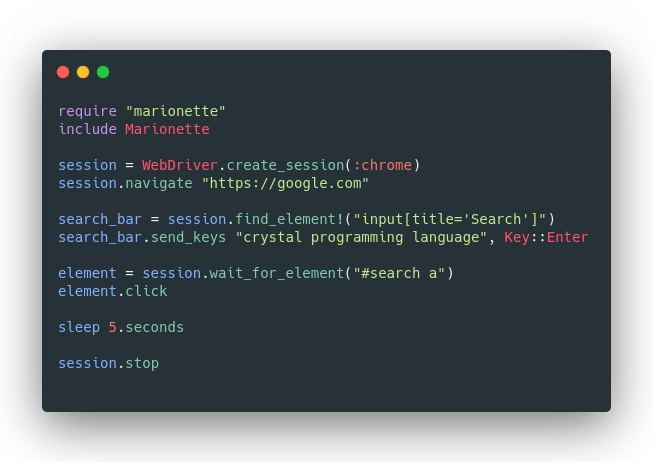
Marionette is a one-size-fits-all approach to WebDriver adapters. It works with most all web driver implementations, including:
- Chrome
- Chromium
- Firefox
- Safari
- Edge
- Internet Explorer
- Opera
- PhantomJS
- Webkit GTK
- WPE Webkit
- Android
watzon6. AbotX
AbotX is a free and open-source powerful C# web crawler that makes advanced crawling features easy to use. AbotX builds upon Abot C# Web Crawler Framework by providing a powerful set of wrappers and extensions.
Features
- Crawl multiple sites concurrently (ParallelCrawlerEngine)
- Pause/resume live crawls (CrawlerX & ParallelCrawlerEngine)
- Render javascript before processing (CrawlerX & ParallelCrawlerEngine)
- Simplified pluggability/extensibility (CrawlerX & ParallelCrawlerEngine)
- Avoid getting blocked by sites (AutoThrottling)
- Automatically tune speed/concurrency (AutoTuning)
sjdirect7. PhantomJS
PhantomJS is a headless web browser scriptable with JavaScript. It runs on Windows, macOS, Linux, and FreeBSD.
It is using QtWebKit as the back-end, it offers fast and native support for various web standards: DOM handling, CSS selector, JSON, Canvas, and SVG.
Note, that PhantomJS's development is suspended.

8. Splash
Splash is a javascript rendering service with an HTTP API. It's a lightweight browser with an HTTP API, implemented in Python 3 using Twisted and QT5.
It's fast, lightweight and state-less which makes it easy to distribute.
scrapinghub9. Splinter
This is a Python-based tool for web application testing. It automates browser actions such as navigating to URLs, filling out forms, and interacting with page elements. Splinter supports various web drivers, including Selenium WebDriver, Google Chrome, and Firefox.
It simplifies the process of writing tests by providing a user-friendly API for controlling browsers, making it a valuable asset for developers and testers focused on ensuring web application functionality.

10. Playwright
Playwright is a Python library for automating web browsers. It allows for end-to-end testing, offering robust capabilities like multi-browser support, including Chromium, Firefox, and WebKit.
Playwright can handle tasks such as web scraping, form submission, and UI testing, providing tools for simulating user interactions and capturing screenshots. Its powerful API supports modern web app testing needs efficiently.
microsoft11. Headless Chrome Crawler
This is an open-source project that offers a distributed crawler powered by Headless Chrome.
Features
- Distributed crawling
- Configure concurrency, delay and retry
- Support both depth-first search and breadth-first search algorithm
- Pluggable cache storages such as Redis
- Support CSV and JSON Lines for exporting results
- Pause at the max request and resume at any time
- Insert jQuery automatically for scraping
- Save screenshots for the crawling evidence
- Emulate devices and user agents
- Priority queue for crawling efficiency
- Obey robots.txt
- Follow sitemap.xml
- [Promise] support
yujiosaka12. hlspy
This is a A simple headless browser based on QtWebEngine (Chromium) as backend
kanishka-linux13. Ferrum - high-level API to control Chrome in Ruby
Ferrum is a Ruby library for automating Chrome. It provides a way to control the browser without needing a driver like Selenium. Ferrum can handle tasks such as navigating web pages, interacting with elements, and capturing screenshots.
It is useful for web scraping, automated testing, and simulating user interactions. Ferrum operates in both headless and non-headless modes, making it versatile for various automation needs.
rubycdp14. chromedp
Chromedp is a faster, simpler way to drive browsers supporting the Chrome DevTools Protocol.
chromedp15. Selenium WebDriver
Selenium is an umbrella project encapsulating a variety of tools and libraries enabling web browser automation. Selenium specifically provides an infrastructure for the W3C WebDriver specification — a platform and language-neutral coding interface compatible with all major web browsers.
SeleniumHQConclusion
Headless browsers have revolutionized the way developers and testers interact with web pages. Their ability to automate, monitor, and optimize web-based tasks without a GUI makes them invaluable in modern web development and testing. By leveraging headless browsers, professionals can achieve greater efficiency, scalability, and precision in their workflows.





{kind=link}